

Databricks on Azure is essential in data, AI and IoT solutions, but the env. automation can be challenging. Azure DevOps is a great tool for automation. Using Pipelines and product CLI integrations can minimise or even remove these challenges. My team is currently working on a cutting edge IoT platform where data flows from edge devices to Azure. We are dealing with data which is sensitive, and under GDPR so no one should have direct access to the data platform in the production environments.
In the project, data is generated by sensors and sent to the cloud by the edge devices. Ingestion, processing and analysis of data are too complicated for the traditional relational databases; for this reason, there are other tools to refine the data. We use DataBricks in our Lambda Architecture to batch process the data at rest and predictive analytics and machine learning. This blog post is about the DataBricks cluster and environment management, and I’ll not go deeper to the architecture or IoT solution.
The Automation Problems
As any reliable project, we have three environments which are development, user acceptance testing (UAT) and production. In my two previous posts, Azure Infrastructure using Terraform and Pipelines and Implement Azure Infrastructure using Terraform and Pipelines, I had an in-depth review and explanation of why and how Terraform solves environment generation and management problems. Let’s have a study the code Terraform provides for Databricks.
resource "azurerm_resource_group" "example" {
name = "example-resources"
location = "West US"
}
resource "azurerm_databricks_workspace" "example" {
name = "databricks-test"
resource_group_name = azurerm_resource_group.example.name
location = azurerm_resource_group.example.location
sku = "standard"
tags = {
Environment = "Production"
}
}Wait a minute, but that is only the empty environment!
What about the Clusters, Pools, Libraries, Secrets and WorkSpaces?
The Solution, DataBricks Automation with Azure DevOps
Fortunately, DataBricks has a CLI which we can be imported for DataBricks environment automation using Azure DevOps Pipelines. The Pipelines enable us to run PowerShell or Bash scripts as a job step. By using the CLI interfaces in our Bash Script, we can create, manage and maintain our Data bricks environments. This approach will remove the need to do any manual work on the Production DataBricks Work Space. Let’s review the bash script.
#!/bin/bash
set -e
CLUSTER_JSON_FILE="./cluster.json"
INSTANCE_POOL_JSON_FILE="./instance-pool.json"
WAIT_TIME=10
wait_for_cluster_running_state () {
while true; do
CLUSTER_STATUS=$(databricks clusters get --cluster-id $CLUSTER_ID | jq -r '.state')
if [[ $CLUSTER_STATUS == "RUNNING" ]]; then
echo "Operation ready."
break
fi
echo "Cluster is still in pending state, waiting $WAIT_TIME sec.."
sleep $WAIT_TIME
done
}
wait_for_pool_running_state () {
while true; do
POOL_STATUS=$(databricks instance-pools get --instance-pool-id $POOL_INSTANCE_ID | jq -r '.state')
if [[ $POOL_STATUS == "ACTIVE" ]]; then
echo "Operation ready."
break
fi
echo "Pool instance is still in not ready yet, waiting $WAIT_TIME sec.."
sleep $WAIT_TIME
done
}
arr=( $(databricks clusters list --output JSON | jq -r '.clusters[].cluster_name'))
echo "Current clusters:"
echo "${arr[@]}"
CLUSTER_NAME=$(cat $CLUSTER_JSON_FILE | jq -r '.cluster_name')
# Cluster already exists
if [[ " ${arr[@]} " =~ $CLUSTER_NAME ]]; then
echo 'The cluster is already created, skipping the cluster operation.'
exit 0
fi
# Cluster does not exist
if [[-z "$arr" || ! " ${arr[@]} " =~ $CLUSTER_NAME ]]; then
printf "Setting up the databricks environment. Cluster name: %s\n" $CLUSTER_NAME
#Fetching pool-instances
POOL_INSTANCES=( $(databricks instance-pools list --output JSON | jq -r 'select(.instance_pools != null) | .instance_pools[].instance_pool_name'))
POOL_NAME=$(cat $INSTANCE_POOL_JSON_FILE | jq -r '.instance_pool_name')
if [[ -z "$POOL_INSTANCES" || ! " ${POOL_INSTANCES[@]} " =~ $POOL_NAME ]]; then
# Creating the pool-instance
printf 'Creating new Instance-Pool: %s\n' $POOL_NAME
POOL_INSTANCE_ID=$(databricks instance-pools create --json-file $INSTANCE_POOL_JSON_FILE | jq -r '.instance_pool_id')
wait_for_pool_running_state
fi
if [[ " ${POOL_INSTANCES[@]} " =~ $POOL_NAME ]]; then
POOL_INSTANCE_ID=$(databricks instance-pools list --output JSON | jq -r --arg I "$POOL_NAME" '.instance_pools[] | select(.instance_pool_name == $I) | .instance_pool_id')
printf 'The Pool already exists with id: %s\n' $POOL_INSTANCE_ID
fi
# Transforming the cluster JSON
NEW_CLUSTER_CONFIG=$(cat $CLUSTER_JSON_FILE | jq -r --arg var $POOL_INSTANCE_ID '.instance_pool_id = $var')
# Creating databricks cluster with the cluster.json values
printf 'Creating cluster: %s\n' $CLUSTER_NAME
CLUSTER_ID=$(databricks clusters create --json "$NEW_CLUSTER_CONFIG" | jq -r '.cluster_id')
wait_for_cluster_running_state
# Adding cosmosdb Library to the cluster
printf 'Adding the cosmosdb library to the cluster %s\n' $CLUSTER_ID
databricks libraries install \
--cluster-id $CLUSTER_ID \
--maven-coordinates "com.microsoft.azure:azure-cosmosdb-spark_2.4.0_2.11:1.3.5"
wait_for_cluster_running_state
echo 'CosmosDB-Spark -library added successfully.'
echo "Databricks setup created successfully."
fi
First, we will create a Pool for the cluster by waiting for the completion status and the Id. Then we will create a cluster by using the created Pool and wait for the completion. As our cluster gets ready then we will be able to use the cluster id to add Libraries and Workspaces using the following script. there are two support JSON files which include the environment properties.
cluster.json
{
"cluster_name": "main-cluster",
"spark_version": "6.4.x-scala2.11",
"autoscale": {
"min_workers": 1,
"max_workers": 4
},
"instance_pool_id": "FROM_EXTERNAL_SOURCE"
}
pool.json
{
"instance_pool_name": "main-pool",
"node_type_id": "Standard_D3_v2",
"min_idle_instances": 2,
"idle_instances": 2,
"idle_instance_auto_termination": 60
}In our Azure DevOps Pipelines definition first we have to install Python runtime and then DataBricks CLI. By having required environment runtimes then we can run the bash script. Here is the code snippet for the Pipelines step:
- bash: |
python -m pip install --upgrade pip setuptools wheel
python -m pip install databricks-cli
databricks --version
displayName: Install Databricks CLI
- bash: |
cat >~/.databrickscfg <<EOL
[DEFAULT]
host = https://westeurope.azuredatabricks.net
token = $(DATABRICKS_TOKEN)
EOL
displayName: Configure Databricks CLI
- task: ShellScript@2
inputs:
workingDirectory: $(Build.SourcesDirectory)/assets/databricks
scriptPath: $(Build.SourcesDirectory)/assets/databricks/setup.sh
args: ${{ parameters.project }}-${{ parameters.workspace }}
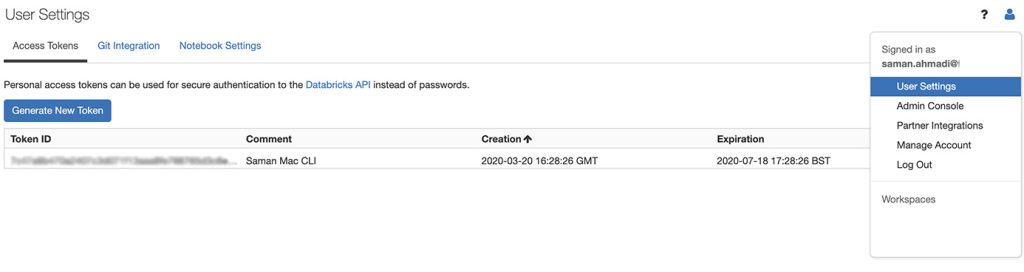
displayName: Setup DatabricksTo be able to run the script against the Databricks environment you need a token. The token can be generated under the workspace and user settings.
The environment variables and settings are in JSON files, and the complete solution for DataBricks Automation with Azure DevOps Pipelines and support tool files are available from my GitHub repository.

