AKS Federated identity credentials can access Azure resources like Key Vault or Storage account in the Kubernetes Pods without providing account credentials or connection strings in the code.
Azure Kubernetes Service, or AKS, is a managed Kubernetes platform service which provides an environment for cloud-native apps. The service interoperates with Azure security, identity, cost management and migration services. The platform usage is famous in micro-service applications, but also a perfect environment for long-running data processes and orchestrations.
Regardless of functionality, Azure cloud-native applications require access to other services to perform the CRUD operations on files in a Data Lake or Storage Account or fetch a secret from a Key Vault. The code usually takes a connection string or credentials to create a client for the service and uses those credentials to perform the task. Here are some examples.
A Python code to create ClientSecret credentials using a Service Principal client id and secret.
from azure.identity import ClientSecretCredential
token_credential = ClientSecretCredential(
self.active_directory_tenant_id,
self.active_directory_application_id,
self.active_directory_application_secret
)
# Instantiate a BlobServiceClient using a token credential
from azure.storage.blob import BlobServiceClient
blob_service_client = BlobServiceClient(account_url=self.oauth_url, credential=token_credential)A C# code to create a blob service client using the connection string:
BlobServiceClient blobServiceClient = new BlobServiceClient("DefaultEndpointsProtocol=https;AccountName=<your-account-key>;AccountKey=<your-account-key>;EndpointSuffix=core.windows.net");The Default Credentials
The DefaultAzureCredential() method under Azure.Identity namespace would be the best option to get the current credentials within the current environment context where the code is running. To avoid passing sensitive information to the code or overhead of managing the credentials in the secrets service of Kubernetes. The problem with default credentials would be logging into Azure using the CLI to enable the security context for the method.
AKS Federated Identity
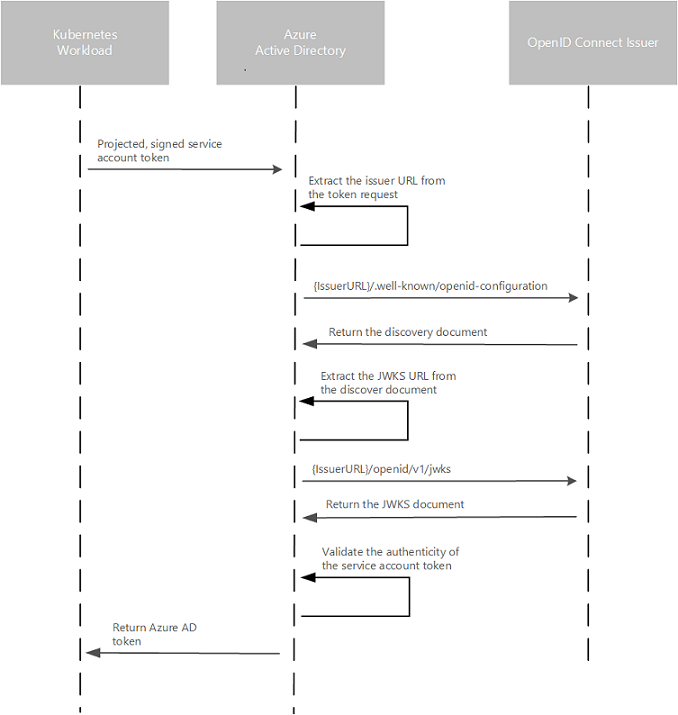
AKS has introduced federated identity to solve the problem of fetching the context for the method. This pod-managed identity allows the hosted workload or application access to resources through Azure Active Directory (Azure AD). For example, a workload stores files in Azure Storage, and when it needs to access those files, the pod authenticates itself against the resource as an Azure-managed identity. This feature works in the cloud and on-premises clusters but is still in preview mode.
Requirements and Configurations
The feature requires the cluster to have the OIDC Issuer enabled, allowing the API server to discover public signing keys. You can use the CLI to update, create or update a cluster using the –enable-oidc-issuer and –enable-managed-identity flags. In Terraform, you can set the oidc_issuer_enabled and workload_identity_enabled to true.
az aks update -g myResourceGroup -n myAKSCluster –enable-oidc-issuer –enable-managed-identity
To get the OIDC which you will need in the next steps use the following CLI command:
az aks show -n myAKScluster -g myResourceGroup --query "oidcIssuerProfile.issuerUrl" -otsv
User Assigned Managed Identity
The next step is to create a User assigned managed identities to enable Azure resources to authenticate to services that support Azure AD authentication without storing credentials in code. The identity can be created using the portal searching for “User Assigned Managed Identity”, Terraform or the CLI:
az identity create --name myIdentity --resource-group myResourceGroup
resource "azurerm_user_assigned_identity" "saman_identity_poc" {
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
name = "saman-cluster-poc"
}
Kubernetes Service Account
As the Azure User assigned identity is created, we have to create a Kubernetes Service Account, which provides an identity for processes that run in a Pod and map to a ServiceAccount object. We have to provide the client if of the created managed identity in the annotations section. The Client id is presented on the Overview page of the User Assigned Managed Identity. Create a service account using the kubectl CLI or Terraform as follows:
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: saman-identity-poc
annotations: azure.workload.identity/client-id: THE CLIENT ID OF THE IDENTITY
type: kubernetes.io/service-account-token
EOFTerraform:
resource "kubernetes_service_account" "aks_poc" {
metadata {
name = "saman-identity-poc"
namespace = "saman"
annotations = {
"azure.workload.identity/client-id" = data.azurerm_user_assigned_identity.wlid_managed_identity.client_id
}
labels = {
"azure.workload.identity/use" = "true"
}
}
}
Federated Identity Credentials
The federation can be created by having the two parts identities from Azure and Kubernetes. For the illustration, I have a screenshot from the Azure portal to see the information required in the User assigned identity. You can navigate this view by selecting the identity created earlier in the portal and choosing “Federated credentials” from the navigation. Click on the “Add Credentials” button on the federated credentials page. Choose “Kubernetes accessing Azure Resources” in the next screen to see the following files.
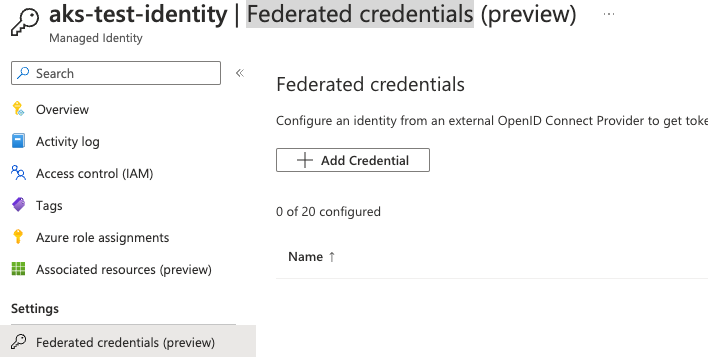
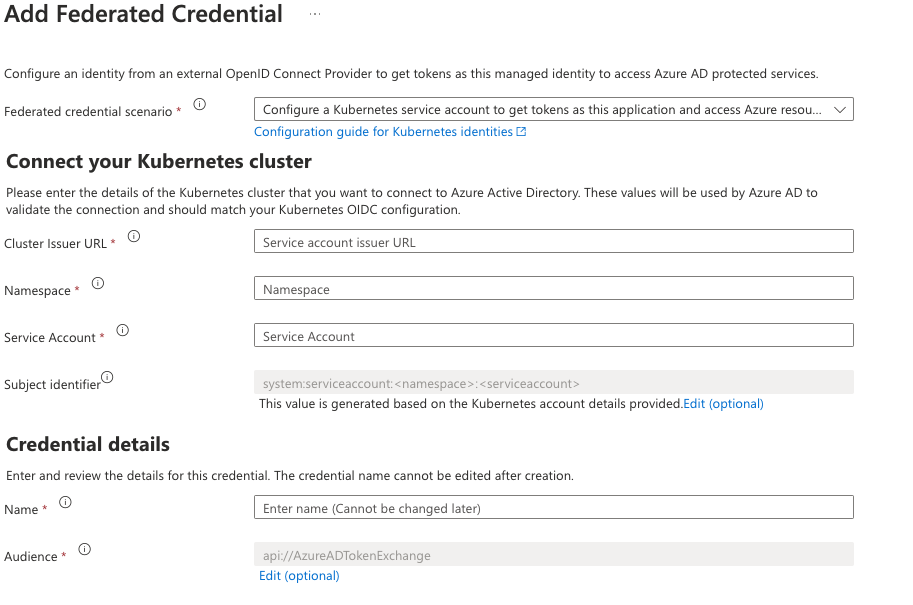
- The cluster Issuer URL is the one we got from the OIDC part.
- The namespace is the one used to create the Kubernetes service account.
- Service Account was created in the previous step using the kubectl. So in my example “
saman-identity-poc“ - The name field is your unique name to give to this federation.
When the fields are filled, press the update button and create the federation. You can achieve the same result using the following Terraform definition:
resource "azurerm_federated_identity_credential" "saman_identity_poc" {
name = "saman-identity-poc-federated-credential"
resource_group_name = azurerm_resource_group.rg.name
parent_id = azurerm_user_assigned_identity.saman_identity_poc.id
issuer = azurerm_kubernetes_cluster.aks_cluster.oidc_issuer_url
subject = "system:serviceaccount:saman:saman-identity-poc"
audience = ["api://AzureADTokenExchange"]
}
AKS Federated Identity Conclution
- Avoid passing credentials and connection strings to your code
- Create a User Assigned Managed Identity
- Create a Kubernetes service account
- Create a federation between the identity and the service account
- When the federation is created, assign roles to the user management identity in the Azure resource and let the Azure identity providers take care of the rest