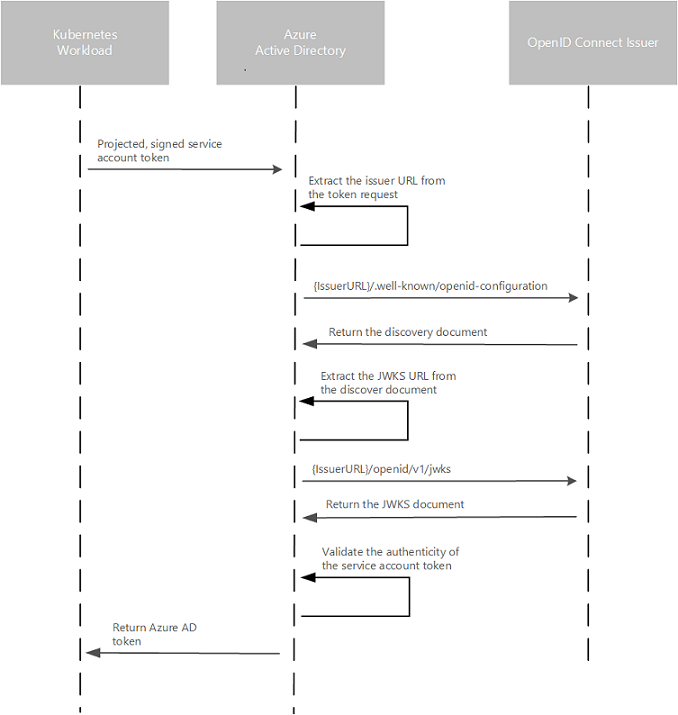
In modern data architectures, the Lakehouse paradigm is gaining strong traction — combining the scale and flexibility of data lakes with the ACID reliability and governance of data warehouses. At the center of this evolution is the comparison between DeltaLake Apache Iceberg v3, two leading table formats shaping the next generation of open data management. Delta Lake (pioneered by Databricks) and Apache Iceberg, which I reviewed in my previous post, continue to evolve rapidly. With the recent release of Iceberg v3 on Databricks, it’s a perfect moment to analyse how these formats compare — and, importantly, how they converge. This analysis builds on insights shared in Databricks’ recent blog post on Iceberg v3 and extends them with additional technical context, architectural interpretation, and practical considerations for modern data lakehouse design.
Why This Comparison Matters
Historically, choosing between Delta Lake and Iceberg meant a trade-off:
- Delta Lake offered deep integration with Databricks, excellent performance, and mature transactional semantics.
- Iceberg provided broad interoperability and standardisation across engines (Spark, Flink, Trino, Presto, etc.).
But as noted in the Databricks blog, Iceberg v3 introduces features that significantly narrow the gap.
Key Technical Enhancements in Iceberg v3 (on Databricks)
According to Databricks, Iceberg v3 brings several flagship features to managed tables, enabled via Unity Catalog: deletion vectors, row-level lineage, and a Variant data type. Let’s unpack these and explain their significance in analytical systems.
Deletion Vectors
- Traditional row-level updates or deletes in Parquet-based tables often require rewriting entire Parquet files — expensive at scale.
- Iceberg v3 supports deletion vectors, which store deletion information separately (in vector files) and merge during reads.
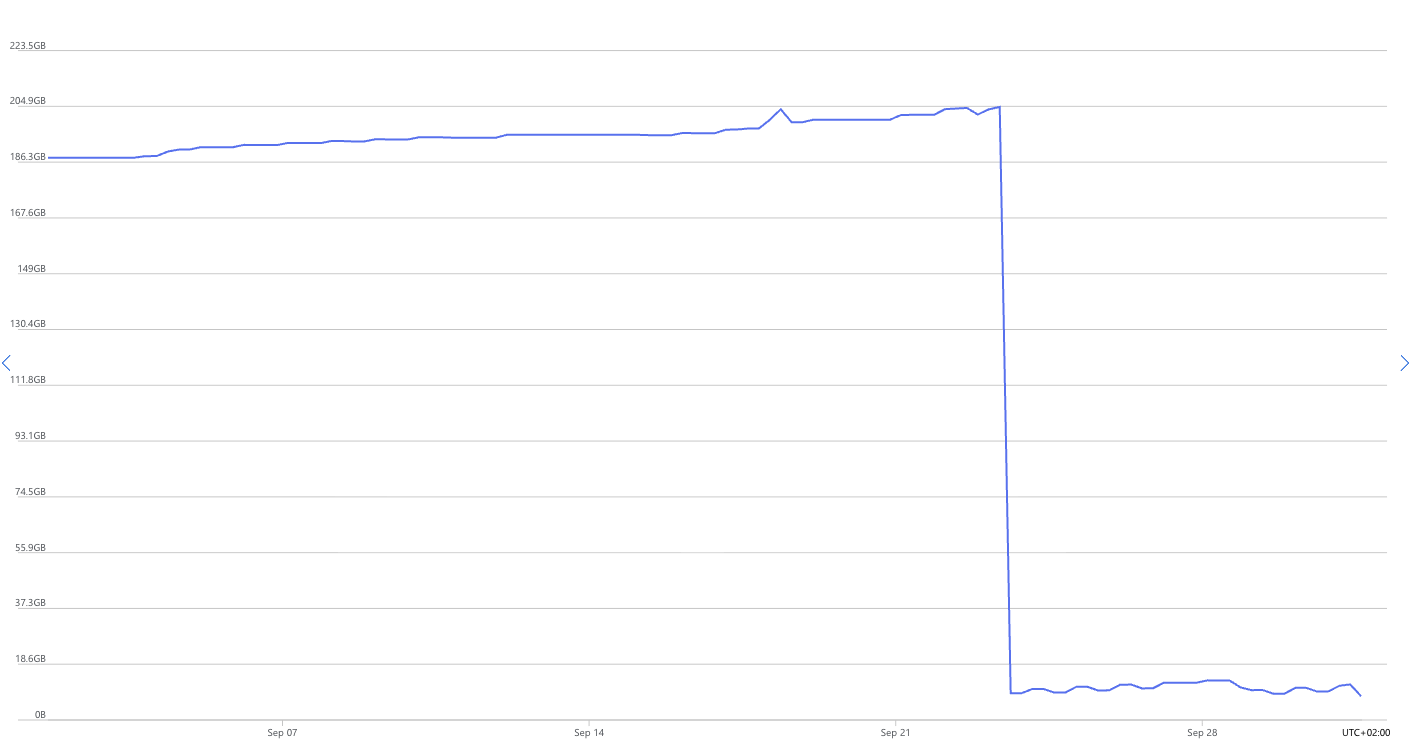
- On Databricks, this can speed up updates by up to 10× compared to standard MERGE operations, because the underlying Parquet data files don’t need to be rewritten.
- This design reflects a strong alignment with Delta Lake’s transactional behaviour, but via an open, standard way.
Row-Level Lineage (Row IDs)
- Iceberg v3 introduces row lineage, where each row has a unique identifier. This is mandatory for v3 tables.
- With row-lineage plus deletion vectors, you can achieve row-level concurrency control: writers can detect conflicts at the row granularity, rather than relying on coarse-grained locking or manual coordination.
- This is a powerful feature for multi-writer environments and complex ETL pipelines, and Databricks claims to be the only engine currently offering this capability at the open-table-format level.
Variant Data Type
- Modern data ingestion often involves semi-structured formats (JSON, XML, nested schemas). Iceberg v3 introduces a VARIANT data type to store such semi-structured data natively.
- On Databricks, ingestion functions support JSON, CSV, XML, and the VARIANT columns can be shredded (flattened) into substructures for efficient columnar querying.
- Crucially, this works across both Delta and Iceberg tables, enabling teams on different query engines to share a single physical dataset without duplication.
- This brings schema flexibility and makes the lakehouse more unified and less rigid.
Unified Metadata / Table Behaviour
- One of the most significant implications of Iceberg v3 is that it aligns core table semantics between Delta Lake and Iceberg: deletion semantics, file layout, and row tracking.
- This reduces the need to pick one format over the other — with Iceberg v3, you can use a single copy of data and query it via either format, with consistent behaviour.
- For organisations, this means avoiding costly data rewrites (petabytes of data) simply because they chose one format early on.
Governance via Unity Catalog
- Iceberg v3, when used on Databricks, is fully integrated with Unity Catalog, enabling centralised governance, audit, and access control across formats (Delta & Iceberg).
- Using Unity Catalog’s Iceberg REST Catalog APIs, external Iceberg engines can interact with managed tables, supporting cross-engine reads/writes.
Delta Lake Evolution and Interoperability
It’s also important to place Delta Lake’s own evolution into context:
- With Delta Lake 3.0, Databricks introduced the Universal Format (UniForm), which enables Delta tables to be exposed (read) as if they were Iceberg or Hudi.
- This strategy—the “universal format”—helps eliminate format fragmentation and reduces the need for full data conversion between formats: Delta can act as a canonical storage layer, but clients can read via open formats.
- Combining Delta’s performance optimisations (with Databricks’ native runtime) and the open interoperability of Iceberg (via UniForm or v3), the lakehouse becomes truly cross-engine and future-ready.
When to Use Which Format — A Technical Lens
Given the above, here’s a refined, technical decision framework for choosing Delta Lake vs Iceberg v3 in a Databricks-centric architecture:
- All workloads run on Databricks (SQL analytics, ML, ETL): Use Delta Lake (native) for maximum performance and simplicity. Consider writing in Delta, exposing via UniForm, or even migrating to Iceberg v3 only when cross-engine needs arise.
- Multi-engine (e.g., Spark + Trino + Flink): Use Iceberg v3 with Unity Catalog: you benefit from row-level concurrency, deletion vectors, and variant types while maintaining a single data copy.
- Semi-structured ingestion (JSON / XML / logs): Use Iceberg v3 with Variant type: better schema flexibility, performance optimisations via shredding, and unified access across formats.
- Governance-critical environments: Use Unity Catalog-managed Iceberg v3 tables: centralised governance, lineage, and access control across clients/engines.
- Large-scale metadata and multi-table operations: Leverage Iceberg’s metadata tree model and upcoming community features (like adaptive metadata tree) to scale efficiently. Databricks contributions are directly shaping this.
Implications for the Future of Open Lakehouses
- Convergence Rather Than Divergence: With Iceberg v3 and UniForm, Databricks is pushing toward a future where format choice does not force data duplication or compromise on features.
- Open Standards & Community Leadership: Databricks is contributing key capabilities (deletion vectors, lineage, variant) back to the Iceberg community.
- Metadata Innovations: The next frontier includes community-driven improvements like the adaptive metadata tree (introduced at Iceberg Summit), which promises to reduce metadata overhead and accelerate operations at scale.
- Single Data Copy, Multi-Engine Access: This architecture reduces storage cost, simplifies architecture, and enables diverse workloads without fragmentation.
Conclusion
The release of Apache Iceberg v3 on Databricks is a watershed moment in the evolution of the data lakehouse paradigm. By bridging the semantic gap between Iceberg and Delta Lake — through deletion vectors, row lineage, and variant types — Databricks enables unified, performant, and governed data architectures.
For data architects and engineers, the decision between Delta Lake and Iceberg is less about locking in on a single format and more about choosing the right engine and governance layer, while maintaining future flexibility.
If you’re building or modernizing a Lakehouse, consider adopting Iceberg v3 (on Unity Catalog) where cross-engine interoperability, semi-structured data, and fine-grained concurrency matter. For purely Databricks-native workloads, continue leveraging Delta Lake, but design with UniForm or Iceberg v3 in mind — giving you a flexible path forward with minimal data duplication.